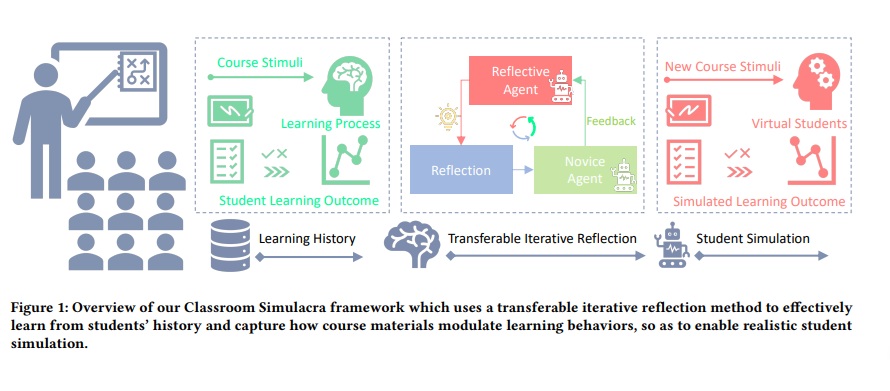
Student simulation supports educators to improve teaching by interacting with virtual students. However, most existing approaches ignore the modulation effects of course materials because of two challenges: the lack of datasets with granularly annotated course materials, and the limitation of existing simulation models in processing extremely long textual data. To solve the challenges, we first run a 6-week education workshop from N = 60 students to collect fine-grained data using a custom built online education system, which logs students’ learning behaviors as they interact with lecture materials over time. Second, we propose a transferable iterative reflection (TIR) module that augments both prompting-based and finetuning-based large language models (LLMs) for simulating learning behaviors. Our comprehensive experiments show that TIR enables the LLMs to perform more accurate student simulation than classical deep learning models, even with limited demonstration data. Our TIR approach better captures the granular dynamism of learning performance and inter-student correlations in classrooms, paving the way towards a “digital twin” for online education.
https://dl.acm.org/doi/10.1145/3706598.3713773
On the student’s side, students were required to first go through a gaze calibration process and then collected facial expressions for cognitive information detection. To collect gaze information from the students, we used the service from GazeRecorder6 . Around 28 gaze positions were provided from the service per second, which were then labeled as fixations or saccades using a velocity-based method [13]. Meanwhile, the system sent facial expressions to the server for cognitive information detection every second. The students’ side uploaded all gaze information and cognitive information every five seconds. The algorithm we used to transform raw gaze into fixations was from [13]. The basic idea was to calculate a velocity threshold, and gaze points with velocity below were labeled as fixations. The confusion information of students was detected using a support vector machine (SVM). Before the lecture started, students were asked to make confused expressions and neutral expressions. Collected data were cropped to focus on the eyebrow-eye region and then fed to principal component analysis (PCA) to extract features. An SVM was trained based on the features to classify either confused or neutral expressions. Attention detection was facilitated by gaze detection, confusion detection, and browser built-in properties. When the user switched to another tab or application, document.visibilityState in the browser became hidden. This property was checked together with confusion detection. When the confusion detection algorithm on the server failed to detect a face, which meant the student’s face was out of the camera, the system then asserted the student to be not attentive. Thirdly, when the gaze of the student fell out of the screen, the student was labeled as not attentive as well.