Working memory involves the temporary retention of information over short periods. It is a critical cognitive function that enables humans to perform various online processing tasks, such as dialing a phone number, recalling misplaced items’ locations, or navigating through a store. However, inherent limitations in an individual’s capacity to retain information often result in forgetting important details during such tasks. Although previous research has successfully utilized wearable and assistive technologies to enhance long-term memory functions (e.g., episodic memory), their application to supporting short-term recall in daily activities remains underexplored. To address this gap, we present Memento, a framework that uses multimodal wearable sensor data to detect significant changes in cognitive state and provide intelligent in situ cues to enhance recall. Through two user studies involving 15 and 25 participants in visual search navigation tasks, we demonstrate that participants receiving visual cues from Memento achieved significantly better route recall, improving approximately 20-23% compared to free recall. Furthermore, Memento reduced cognitive load and review time by 46% while also achieving a substantial reduction in computation time, offering an average 75% effective compared to computer vision-based cues selection approaches.
In this work, we proposed and evaluated a first-of-its-kind system which extracts moments or highlights from a user’s short-term episodes to cue those important moments during visuospatial working memory tasks, intending to improve the memory recall of those moments. Through a system implementation and two separate userstudies, we establish that improving one’s recall with intelligent cueing is possible during visual search and wayfinding navigation.
https://dl.acm.org/doi/10.1145/3699682.3728340
p>Study Environments:
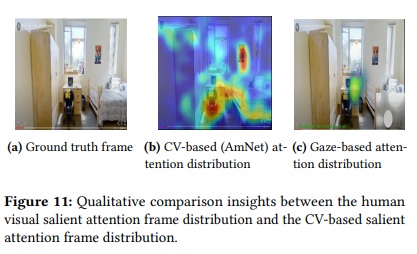
Similar to prior work in wayfinding and route tracing , we employed a desktop-based virtual environment where participants navigated through four distinct scenarios: (a) an indoor dorm, (b) a familiar suburban campus area, (c) the downtown area of a mid-size U.S. city (Baltimore), and (d) a dense cosmopolitan city (NYC). Participants wore Emotiv Insight headsets equipped with EEG and IMU sensors, along with Shimmer sensors for GSR and PPG data collection. Throughout the navigation tasks, screen recordings and gaze fixations were captured using the freely available Gaze Recorder , which provided ground truth on participants’ visual attention and detected artifacts such as eye blinks. The Gaze Recorder features a user-friendly gaze calibration interface consisting of two steps: (i) Facial synchronization, where participants align their faces by following red points on the screen, and (ii) Gaze calibration, where participants track 16 points appearing across the screen. During task performance, fixation heatmaps were generated for areas of interest (AOI). Task start and end times were recorded to synchronize multimodal data streams from the Shimmer and Emotiv Insight headsets, and each session was recorded using an Akaso action camera5 , serving as a ground truth reference for further analysis.